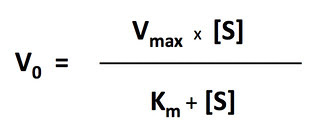When I started this series of posts my goal was to see if I could generate precise data with a proven classroom lab. The data precision that is possible with the yeast catalase lab provides a unique opportunity where data analysis skills can be productively explored, practiced and understood. My contention was that this is the ideal lab to focus not just on content, not just on experimental design, but also to introduce relatively sophisticated data analysis. To be up front about it, I had only a hint of how rich this lab is for doing just that. Partly , this is because in my years of teaching high school biology I covered most of the enzyme content in class activities and with 3D visualizations, focusing on the shape of enzymes but neglecting enzyme kinetics. That would be different if I were teaching today—I’d focus more on the quantitative aspects. Why? Well, it isn’t just to introduce the skills but it has more to do with how quantitative methods help to build a deeper understanding of the phenomena you are trying to study. My claim is that your students will develop a deeper understanding of enzymes and how enzymes work in the grand scheme of things if they follow learning paths that are guided and supported by quantitative data. This post is an example.
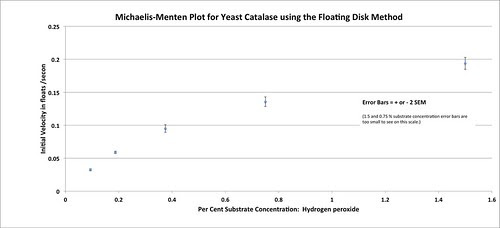
The last post focused on plotting the data points as rates, along with some indication of the variability in each measurement in a plot like this.
As I said before, I would certainly be happy if most of my students got to this point as long as they understood how this graph helps them to describe enzyme reactions and interpret others work.
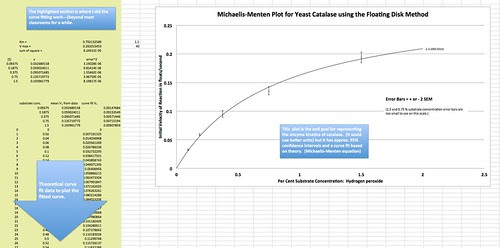
But a graph like this begs to have a line of best fit–a curve that perhaps plots the relationship implied by our data points.
Something like this.
One of the early lessons on model building in my current Research Methods course involves taking data we have generated with a manipulative model (radioactive decay) to generate a predictive model. The students plot their data points and then try to find the mathematical expression that will describe the process best. Almost always, my students ask EXCEL to generate a line of best fit based on the data. Sometimes they pick linear plots, sometimes exponential, sometimes log plots and sometime power plots. These are all options in EXCEL to try and fit the data to some mathematical expression. It should be obvious that the process of exponential decay is not best predicted with multiple types of expressions. There should be one type of expression that most closely fits the actual physical phenomenon–a way of capturing what is actually going on. Just picking a “treandline” based on how well it visually fits the current data without considering the actual phenomenon is a very common error or misconception. You see, to pick or develop the best expression requires a deep understanding of the process being described. In my half-life exercise, I have the students go back and consider the fundamental things or core principles that are going on. Much like the process described by Jungck, Gaff and Weisstein:
“By linking mathematical manipulative models in a four-step process—1) use of physical manipulatives, 2) interactive exploration of computer simulations, 3) derivation of mathematical relationships from core principles, and 4) analysis of real data sets…”
Jungck, John R., Holly Gaff, and Anton E. Weisstein. “Mathematical manipulative models: In defense of “Beanbag Biology”.” CBE-Life Sciences Education 9.3 (2010): 201-211.
The point is that we are really fitting curves or finding a curve of best fit–we are really trying to see how well our model will fit the real data. And that is why fitting this model takes this lab to an entirely new level. But how are you going to build this mathematical model?
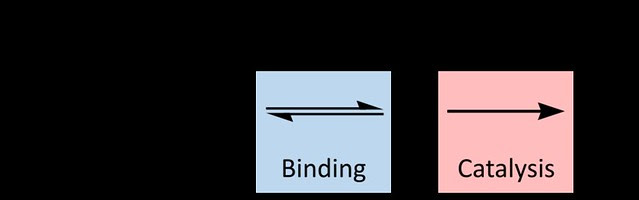
Remember that we started with models that were more conceptual or manipulative. And we introduced a symbolic model as well that captured the core principles of enzyme action:
By Thomas Shafee (Own work) [CC BY 4.0 (http://creativecommons.org/licenses/by/4.0)], via Wikimedia Commons
Now how do we derive a mathematical expression from this? I’m not suggesting that you should necessarily unless you feel comfortable doing so but I’ll bet there are kids in your class that can given a bit of guidance. You may not feel comfortable providing the guidance. But in this day of “just ask Google” you can provide that guidance in the form of a video discussion from the Khan Academy designed to help students prepare for the MCAT. Don’t let that scare you off. Here are two links that take the symbolic model and derive a mathematical expression–not just any expression—the Michaelis-Menten equation for enzyme kinetics. You or your students will no doubt need to view these more than once but the math is not that deep—not if your students are exploring calculus or advanced algebra. It is really more about making assumptions and how those assumptions simplify things so that with regular algebra you can generate the Michaelis-Menten equation.
Of course, you don’t even have to go through the derivation you could just provide the equation.
The important thing is that students understand where this equation comes from—it doesn’t come out of thin air and it is based on the same core principles they uncovered or experienced if they did the toothpickase manipulation–it is just quantified now. So how do I use this equation to actually see how well my data “fits”? If it were a linear expression that would be easy in Excel or any spreadsheet package but what about non-linear trend lines? I can tell you that this expression is not part of the trend line package you’ll find in spreadsheets.
I’ve got to admit, I spent too many years thinking that generating best-fit curves from non-linear expressions like the M-M equation was beyond the abilities of me or my students. But again “Ask Google” comes to the rescue. If you google “using solver for non-linear curve fitting regression” you’ll end up with lots of videos and even some specific to the Michaelis-Menten equation. It turns out EXCEL (and I understand Google Sheets) has an add-on called Solver that helps you find the best fit line. But what does that mean? Well it means that you need to manipulate the parameters in the M-M equation to generate a line until it mostly fits your data–to see if the model is an accurate description of what you measured. What parameters are these?
Look at the equation:
V0 equals the rate of the reaction at differing substrate concentrations–the vertical axis in the plots above.
Vmax equals the point at which all of the enzyme is complexed with the substrate–the maximum rate of the reaction with this particular enzyme at this particular enzyme concentration (that is enzyme concentration not substrate)
Km equals the concentration of the substrate where the rate of reaction is 1/2 of Vmax
[S] equals the substrate concentration, in this case the H2O2
Two of these parameters are variables—one is our experimental or explanatory variable, the concentration of H2O2 and the other is our response variable, the rate of the reaction. Some folks prefer independent and dependent variable. This is what we graph on our axis.
The other two parameters are constants and the help to define the curve. More importantly, these are constants for this particular enzyme at this particular enzyme concentration for this particular reaction. These constants will be for different enzymes, different concentrations or reactions with inhibitors, competitors, etc. In other words it is these constants that help us to define our enzyme properties and provide a quantitative way to compare enzymes and enzyme reactions. You can google up tables of these values on the web. from: Biochemistry, 5th ed. Berg JM, Tymoczko JL, Stryer L.
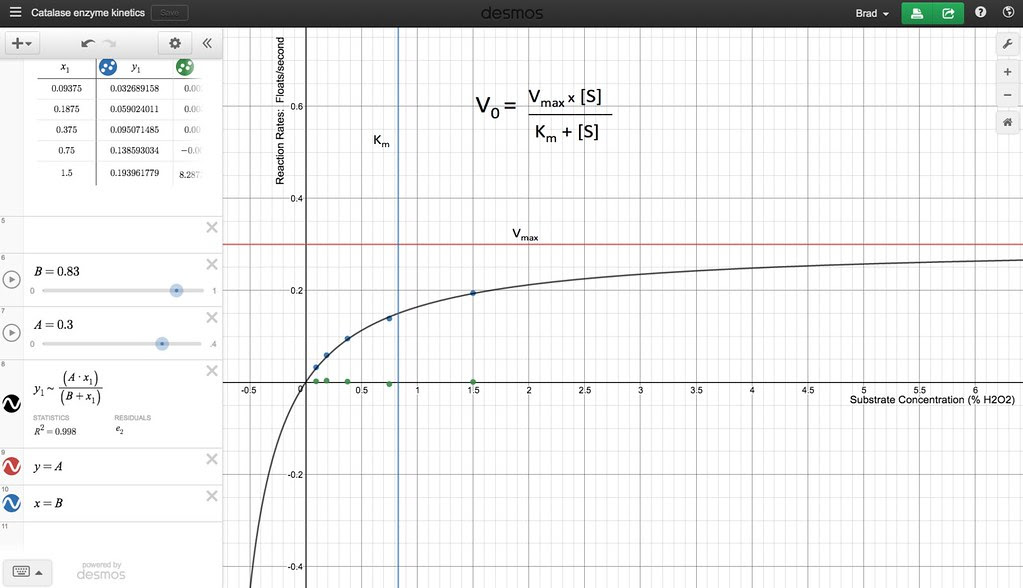
I’ve also taken advantage of a web based math application DESMOS which is kind of a graphing calculator on the web. While I can create sliders to manipulate the constants in the equation, Km and Vmax to make a dynamic spreadsheet model it is a lot easier in DESMOS and DESMOS lets me share or embed the interactive equation. Scroll down in the left hand column to get to the sliders that change the constants.
You can also just go to Desmos and play with it there
I had to use A and B and x1 in my equation as symbols.
It is not that difficult to use DESMOS and with my example your students who are familiar with it will be able to make their own model with their own data within DESMOS. Move the sliders around—they represent the values for Km and Vmax in the equation. Notice how they change the shape of the graph. This really brings home the point of how these constants can be used to quantitatively describe the properties of an enzyme and helps to make sense of the tables one finds about enzyme activity. Also, notice the residuals that are plotted in green along the “x-axis”. These residuals are how we fit the curve. Each green dot is the result of taking the difference between the a point on theoretical line with particular constants and variable values and the actual data point. That difference is squared. A fit that puts the green dots close to zero is a very good fit. (BTW, this is the same thing we do in EXCEL with the Solver tool.) Watch as you try to minimize the total residuals as you move the sliders. The other thing that you get with DESMOS is that if you zoom out you’ll find that this expression is actually a hyperbolic tangent…and not an exponential. How is that important?
Well, think back to the beginning of this post when I talked about how my students often just choose their mathematical model on what line seems to fit the data the best–not on an equation developed from first principles like the Michaelis-Menten.
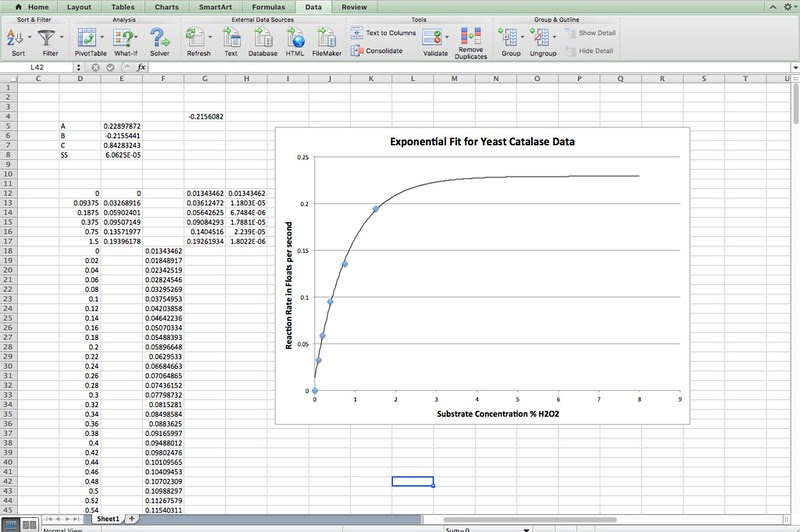
Looking at a plot of the data in this experiment before the curve fitting one might have proposed that an exponential equation might have produced the best fit. In fact, I tried that out just for kicks.
This is what I got.
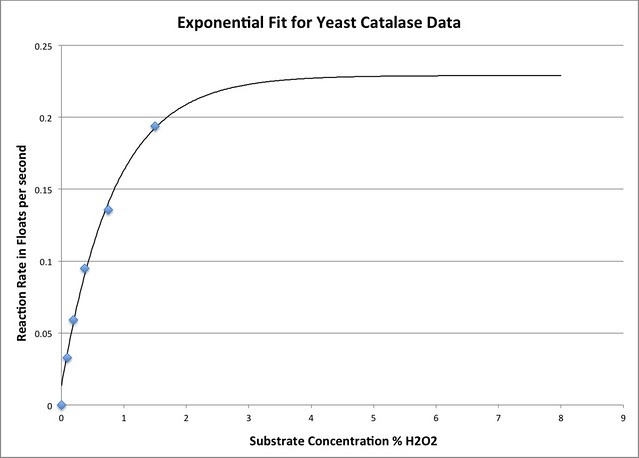
Here’s a close-up:
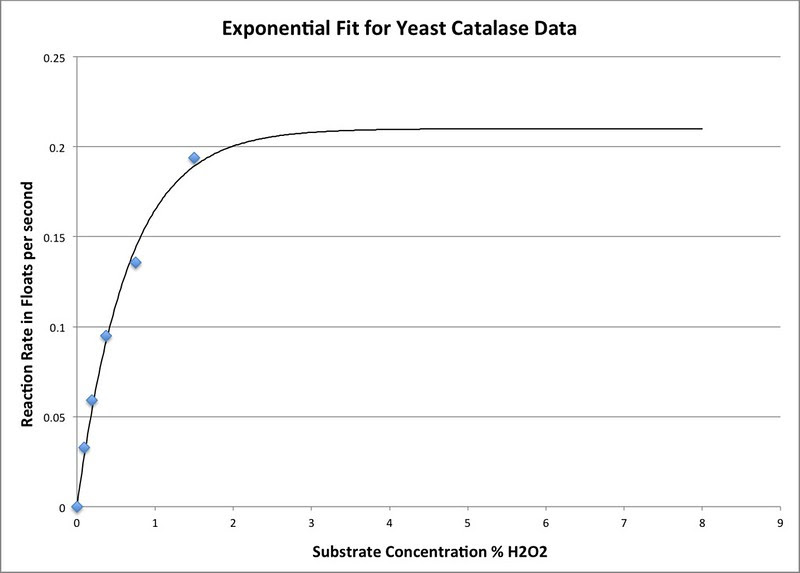
Thinking about the actual experiment and the properties of enzymes there are two things really wrong with this fit although you’ll notice that the “line” seems to go through the data points better than the fit to the Michaelis-Menten equation. 1. Notice that the model line doesn’t go through zero. Hmmmm. Wouldn’t a solution with no Hydrogen peroxide not react with the yeast? That should be tested by the students as a control as part of the experimental design but I can tell you that the disk will not rise in plain water so the plot line needs to go through the origin. I can force that which I have in this fit:
But the second issue with this fit is still there. That is the point where the plot has reached it’s maximum rate. If I had generated data at a 3% substrate concentration I can promise you the rate would have been higher than 0.21 where this plot levels off. While the exponential model looks like a good fit on first inspection it doesn’t hold up to closer inspection. Most importantly the fit is mostly coincidental and not base on an equation developed from first principles. By fitting the data to the mathematical model your students complete the modeling cycle described on page T34 in the AP Biology Investigative Labs Manual, in the Bean Biology paper cited above, and on page 85 in the AP Biology Quantitative Skills Guide.
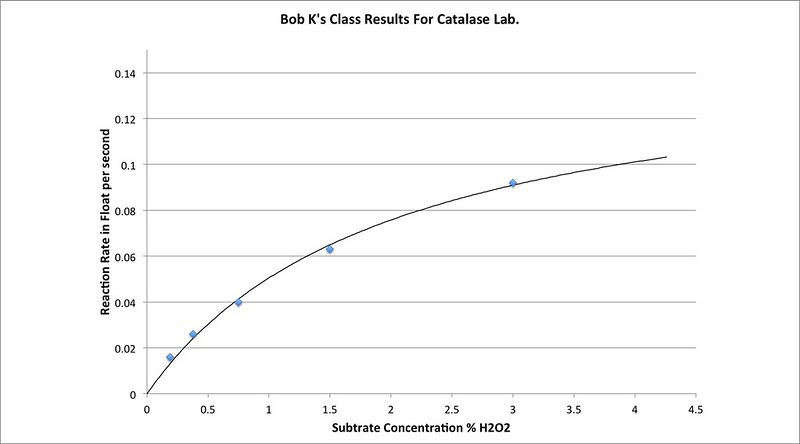
Give model fitting a try—perhaps a little bit a time and not all at once. Consider trying it out for yourself with data your students have generated or consider it as a way of differentiating you instruction. I’ll wrap this up with a model fitted with data from Bob Kuhn’s class that they generated just this month. He posted the data on the AP Biology forum and I created the fit.
The key thing here is that his enzyme concentration (yeast concentration) was quite a bit diluted compared to the data that I’ve been sharing. Note how that has changed the Michaelis-Menten curve and note how knowing the Km and Vmax provides a quantitative way to actually compare these results. (Both constants for this graph are different than for mine)
Hopefully, this sparks some questions for you and your students and opens up new paths for exploring enzymes in the classroom. I’ll wrap this up next week with how one might assess student learning with one more modeling example.